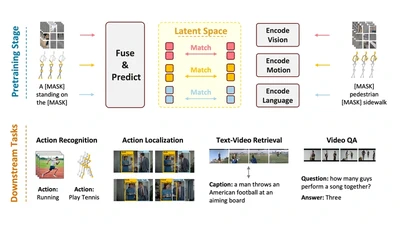
OSKAR: Omnimodal Self-supervised Knowledge Abstraction and Representation
OSKAR is a self-supervised multimodal foundation model that learns in the latent space by predicting masked multimodal features.
mohamed-abdelfattah
OSKAR is a self-supervised multimodal foundation model that learns in the latent space by predicting masked multimodal features.
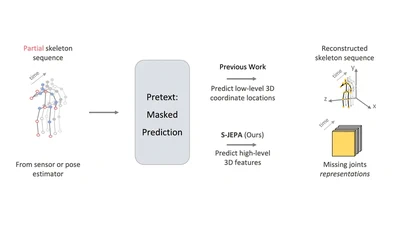
S-JEPA is an instantiation of JEPA for self-supervised skeletal action recognition.