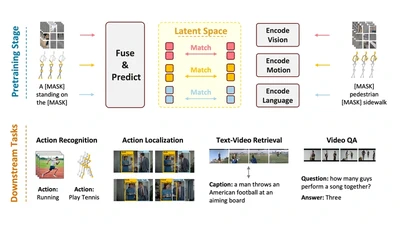
OSKAR: Omnimodal Self-supervised Knowledge Abstraction and Representation
OSKAR is a self-supervised multimodal foundation model that learns in the latent space by predicting masked multimodal features.
mohamed-abdelfattah
OSKAR is a self-supervised multimodal foundation model that learns in the latent space by predicting masked multimodal features.
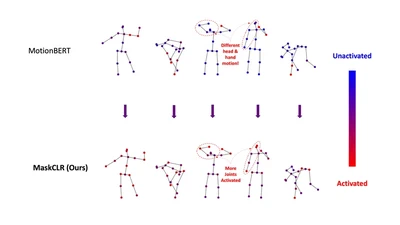
MaskCLR improves the robustness of transformer-based action recognition methods against noisy and incomplete skeletons.
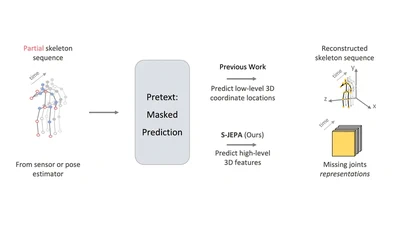
S-JEPA is an instantiation of JEPA for self-supervised skeletal action recognition.
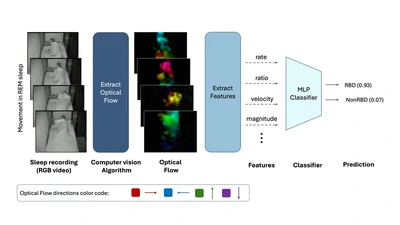
A computer-vision pipeline using conventional 2D sleep-lab cameras to automatically detect iRBD from REM movement dynamics with up to 91.9% accuracy.
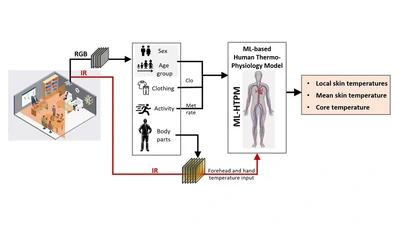
A machine-learning human thermo-physiology model (ML-HTPM) developed to predict thermal response.