S-JEPA: Joint Embedding Predictive Architecture for Self-Supervised Skeletal Action Recognition
Nov 10, 2025·,·
1 min read
Mohamed Abdelfattah
Alexandre Alahi
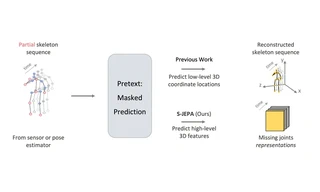
A self-supervised method for skeletal action recognition based on the Joint Embedding Predictive Architecture (JEPA).
Overview
S-JEPA (Joint Embedding Predictive Architecture for Self-Supervised Skeletal Action Recognition) is a research project focused on learning strong skeletal representations without labels. The method instantiates JEPA for skeletal data to predict informative latent targets and improve downstream action recognition.
Authors
- Mohamed Abdelfattah
Alexandre Alahi
Venue
ECCV 2024
One-Sentence Summary
S-JEPA is an instantiation of the Joint Embedding Predictive Architecture (JEPA) for self-supervised skeletal action recognition.
Links
BibTeX
@inproceedings{abdelfattah2024sjepa,
author={Abdelfattah, Mohamed and Alahi, Alexandre},
booktitle={European Conference on Computer Vision (ECCV)},
title={S-JEPA: Joint Embedding Predictive Architecture for Self-Supervised Skeletal Action Recognition},
year={2024},
organization={Springer}
}
Project Status: ✅ Published at ECCV 2024
Project Page: sjepa.github.io
Paper: S-JEPA