Meta Internship
OSMO: Open-vocabulary Self-eMOtion Tracking
Mohamed Abdelfattah
,
CVPR 2026
Egocentric Vision
Multimodal Learning
LLMs
Datasets
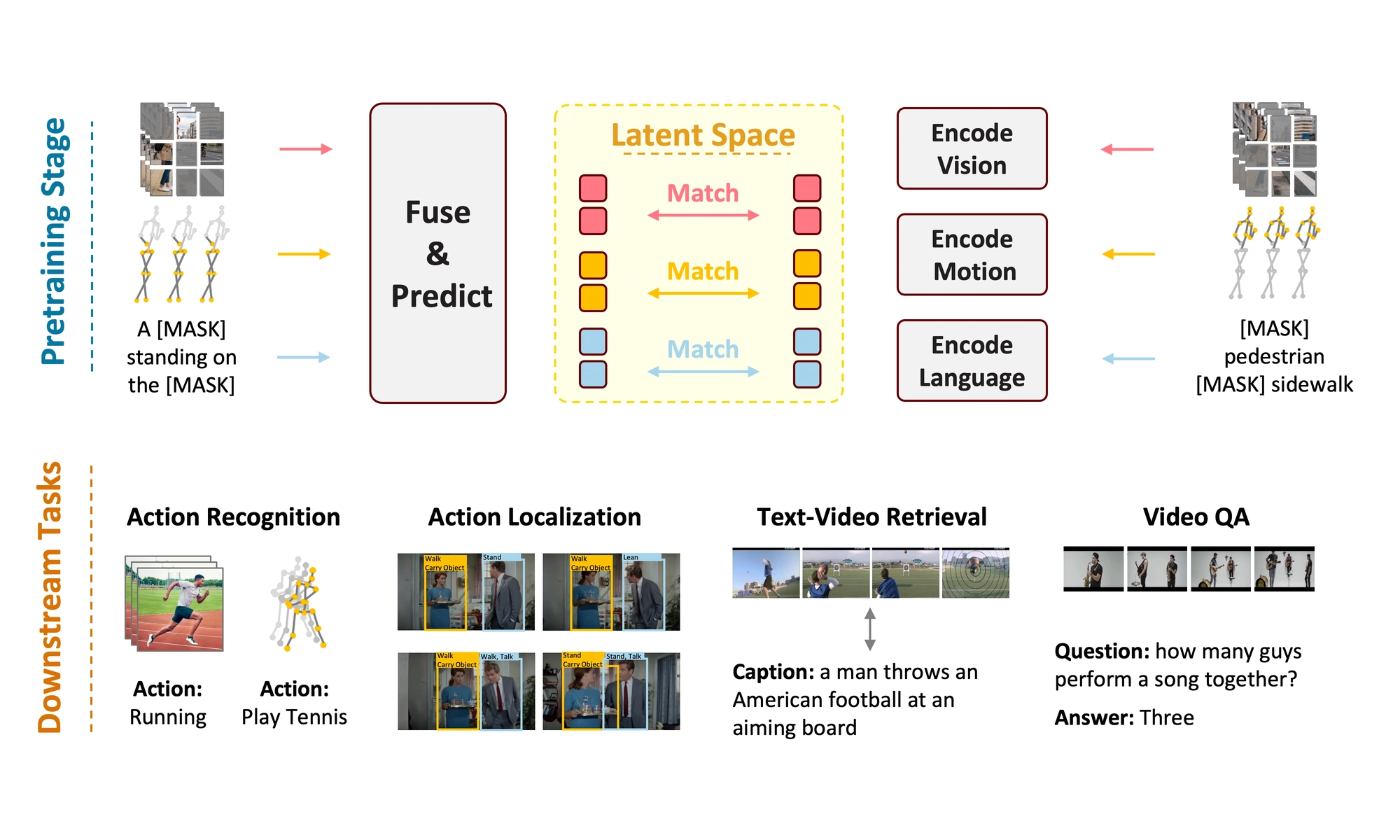
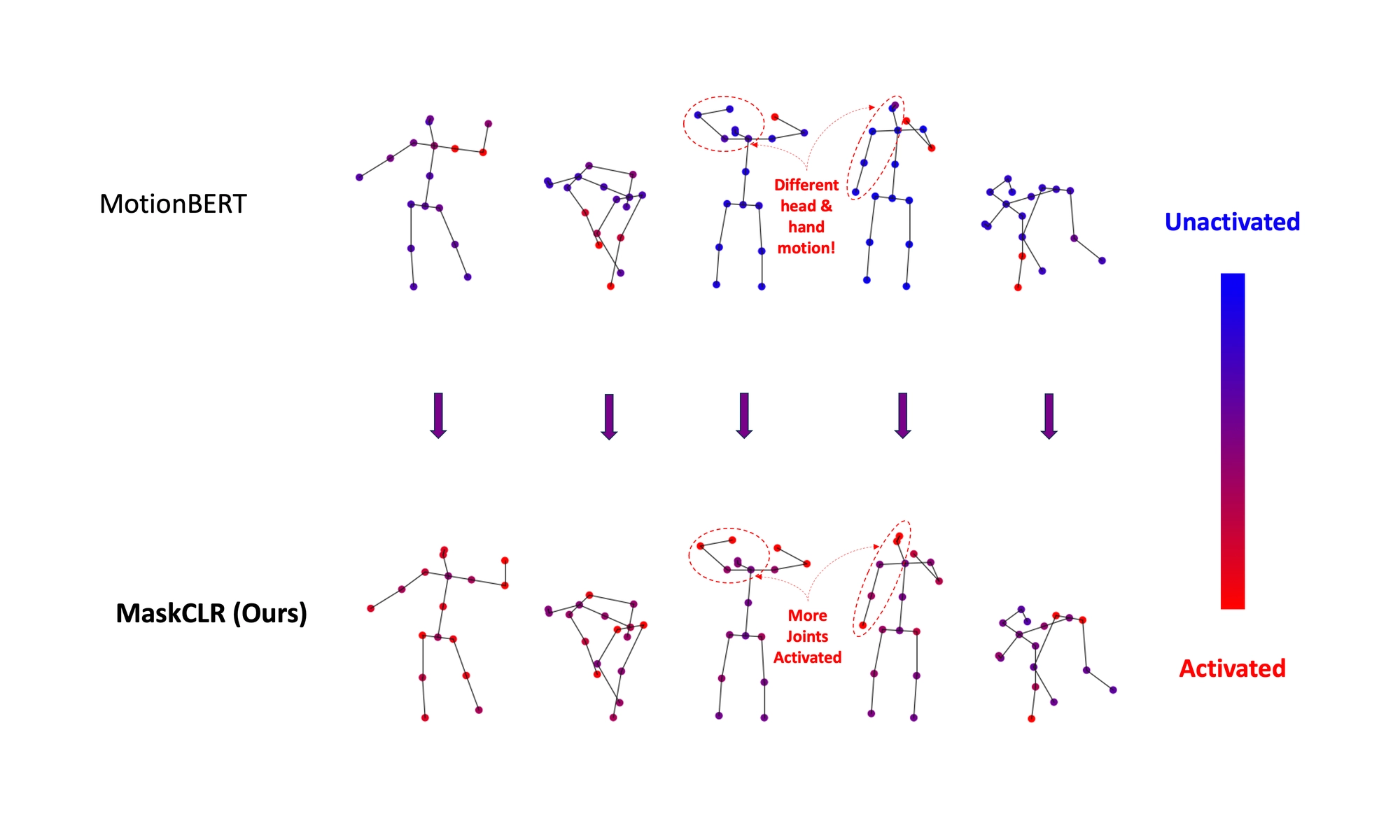
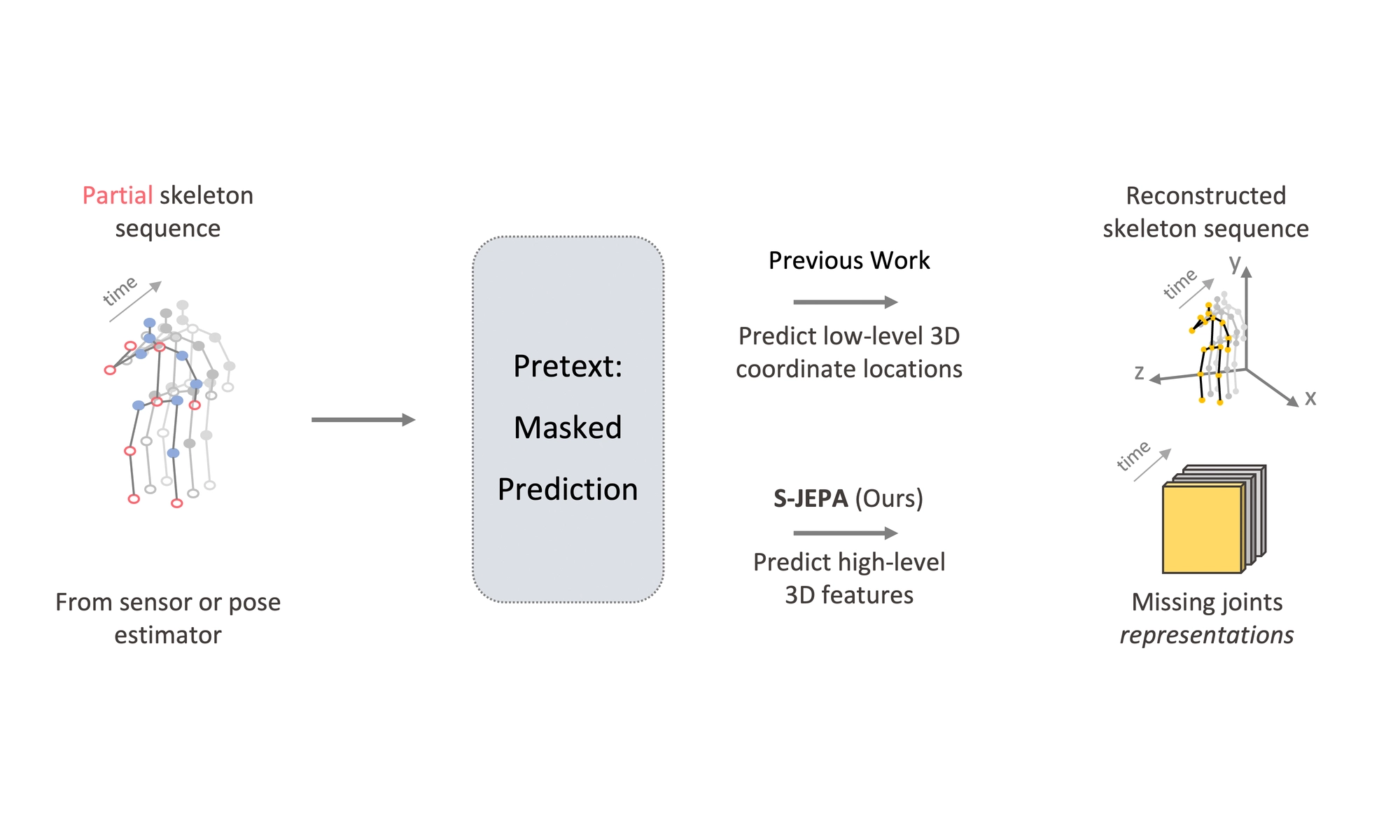
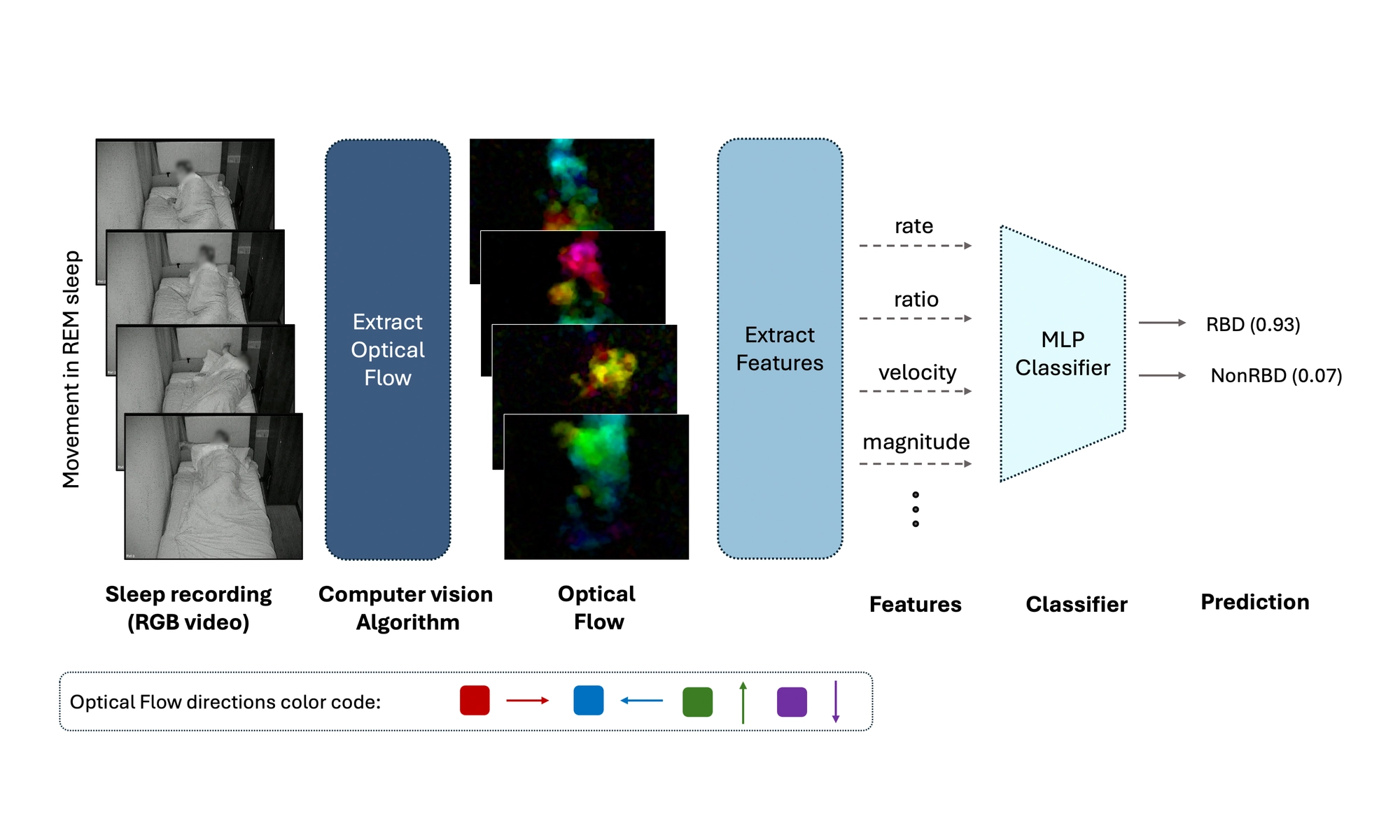
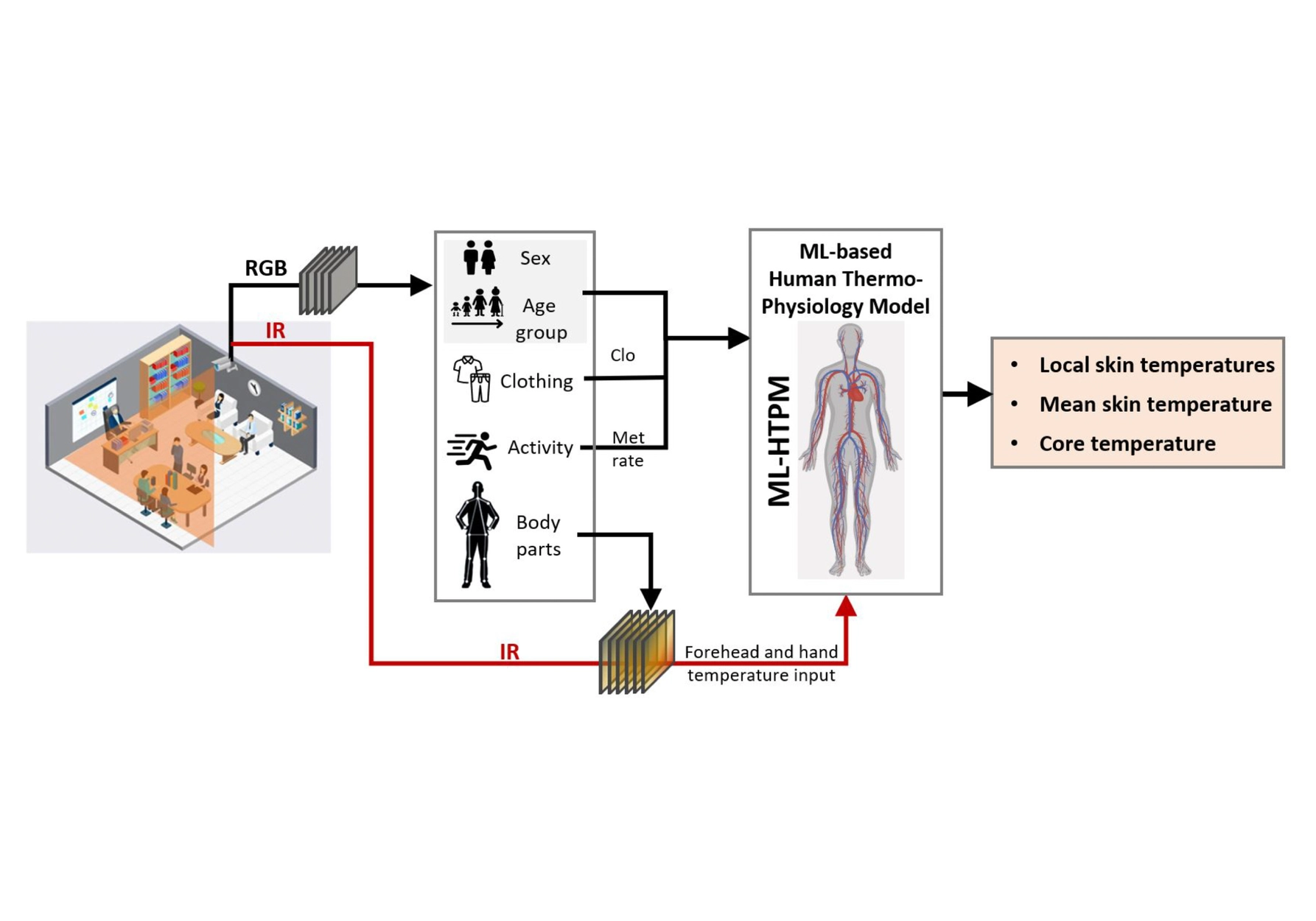
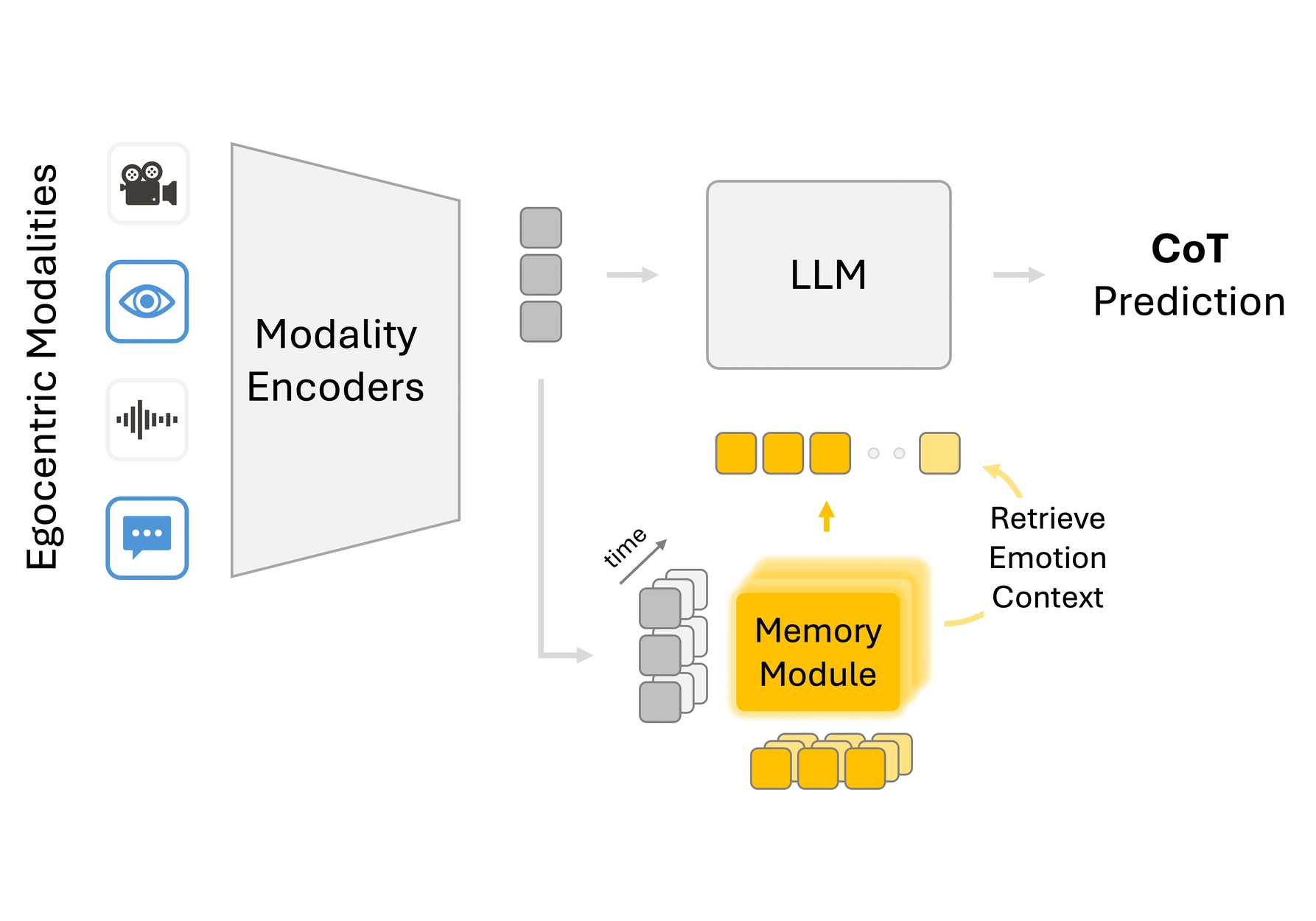
OSIRIS is an egocentric multimodal LLM for continuous, open-vocabulary human-state tracking from smart glasses.